


文档链接: https://docs.georgy.dev/runtime-local-llm/overview
此插件在设备上提供使用 llama.cpp(MIT 许可)进行大型语言模型推理。模型以 GGUF 文件形式存储在项目的内容目录中,并通过 NonUFS 暂存打包构建。
功能:
- 使用编辑器内模型管理器进行简单、直观的设置
- 按名称、文件路径、URL 或元数据加载模型
- 逐个令牌响应流式传输
- 可配置推理
- 多回合对话上下文
- 运行时模型下载
- 内置流行模型系列目录
- 自定义GGUF模型导入
- 编辑器内模型测试window
- 通过 Vulkan(Windows、Linux)和 Metal(Mac、iOS)进行 GPU 加速; Android 和 Meta Quest 上优化的 CPU
- 跨平台兼容性(Windows、Mac、Linux、Android、iOS)
代码模块:
- RuntimeLocalLLM(运行时)
- RuntimeLocalLLMEditor(编辑器)
数量蓝图:0
C++ 类数量:17
网络复制:否
支持的开发平台:
- Windows:是
- Mac:是
- Linux:是
支持的目标构建平台:Win64、 Mac、Linux、LinuxArm64、Android、IOS
示例项目:https://georgy.dev/runtime-local-llm-demo-windows
🧠 在虚幻引擎中完全在设备上运行大型语言模型 – 适用于人工智能驱动的 NPC、动态对话和离线聊天机器人。 跨平台,由 llama.cpp 提供支持
直接在您的虚幻引擎项目中运行GGUF 格式的 LLM(Llama、Mistral、Phi、Gemma、Qwen、TinyLlama 等),没有互联网连接、没有 API 密钥,也没有云运行时依赖。该插件使用完整的蓝图和 C++ API 包装 llama.cpp,加载模型、发送消息并接收逐个令牌的流式响应,所有这些都在带有游戏线程回调的后台线程上进行。
快速链接:
- 🎮 打包演示项目(Windows)
- 📄 文档
- 🎥 YouTube 视频演示
- 💬 Discord 支持聊天
- 📌 插件支持和自定义开发: Solutions@georgy.dev(为团队和组织量身定制的解决方案)
主要功能:
🎯 核心功能:
- 完整离线推理:无需云服务或订阅
- GGUF模型支持:加载任何GGUF格式模型(Llama、Mistral、Phi、Gemma、Qwen、TinyLlama、等)
- 最新的 llama.cpp:在 Fab 上定期更新,以跟上 llama.cpp 版本的步伐,因此始终支持最新的 GGUF 模型格式
- GPU 加速: Windows 和 Linux 上的 Vulkan、Mac 和 iOS 上的 Metal、Mac 和 iOS 上的优化 CPU + 内在函数Android 和 Meta Quest
- 跨平台:Windows、Mac、Linux、Android(包括 Meta Quest)、iOS
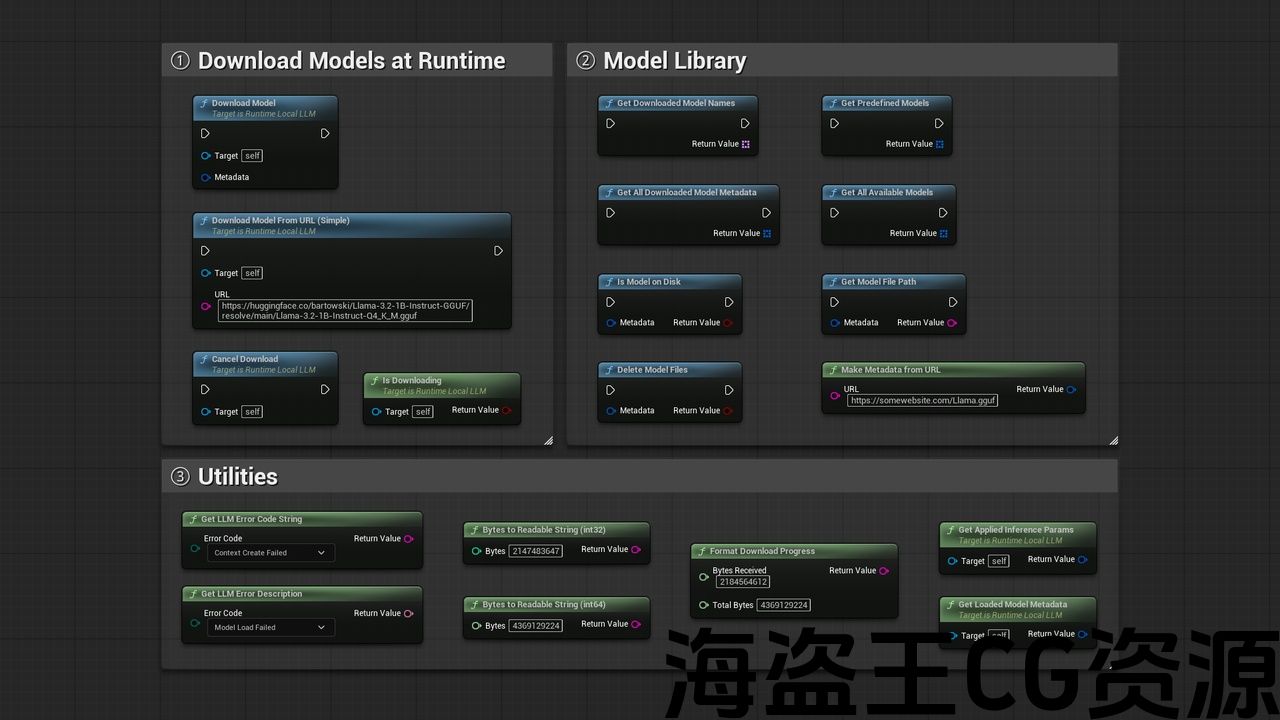
⚡模型加载和管理:
- 按模型加载蓝图中带有下拉选择器的名称
- 从本地文件加载path
- 从 URL 下载并自动加载:如果模型已存在,则跳过下载磁盘
- 仅下载模式用于预缓存模型(例如在加载屏幕或设置上)菜单)
- 编辑器模型管理器:浏览内置目录、下载、导入自定义 GGUF 文件、删除和直接在项目设置中测试模型
🗣️推理与对话:
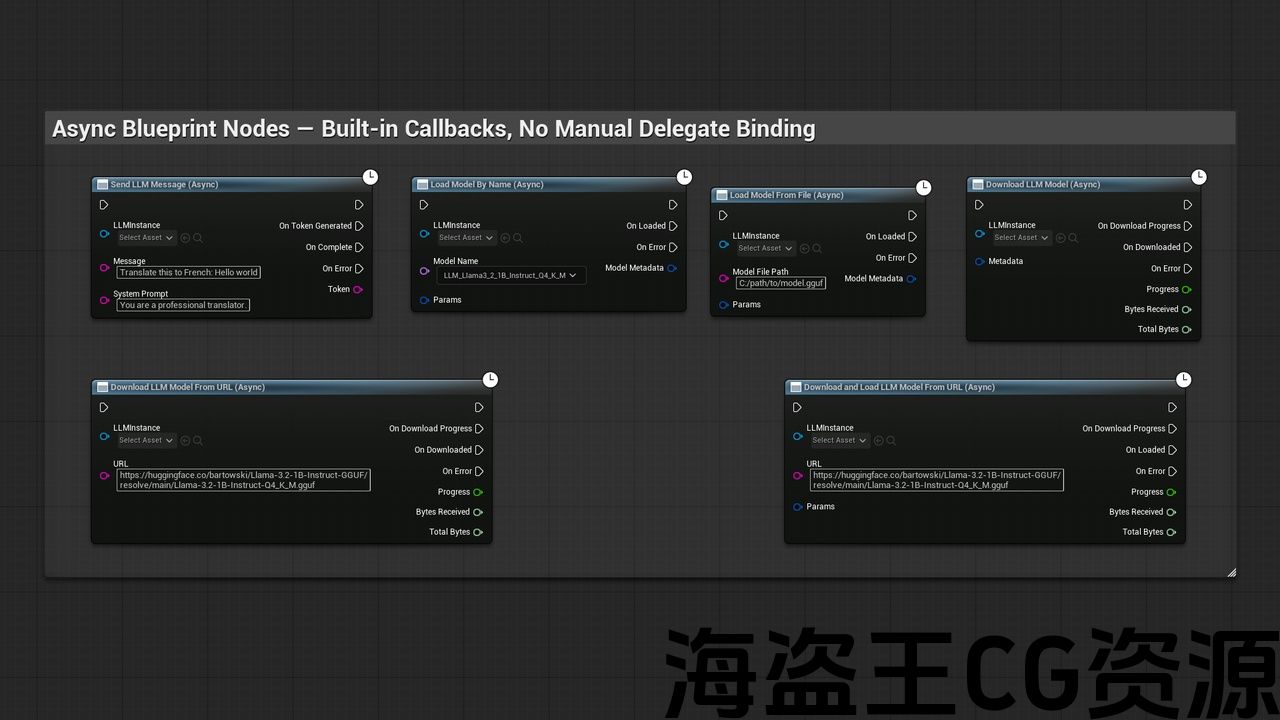
- 逐个令牌流:实时接收每个令牌生成的令牌显示
- 可配置的推理参数:温度、Top-P、Top-K、重复惩罚、GPU层卸载、上下文大小、种子、线程数和系统提示
- 对话上下文管理:通过上下文重置支持维持多轮对话
- 每条消息系统提示覆盖
- 随时取消生成
🛠️开发功能:
- 完整的蓝图和C++ API,具有异步节点和基于委托的回调
- 模型库函数用于查询可用模型、检查磁盘存在、检索元数据
- 自动打包:模型通过 NonUFS staging 随项目一起提供,无需手动配置
- 全面错误处理,带有描述性错误代码
🎮 完美用于:
- NPC对话和动态对话
- 游戏内AI助手和同伴
- 程序内容生成(任务、背景故事、物品描述)
- 语音驱动的游戏工作流程(与运行时语音识别器和运行时文本到语音)
- 离线聊天机器人界面
- 教育和培训应用
- 隐私敏感部署,没有数据离开设备
🌟兼容插件:
- 运行时AI聊天机器人集成器:基于云的LLM API(OpenAI等)
- 运行时文本转语音:用于 LLM 回答的离线 TTS
- 运行时语音识别器:用于语音输入的离线语音到文本
- 运行时 MetaHuman Lip Sync:实时唇形同步TTS 输出
- 运行时音频导入器:运行时音频处理和播放
声明:本站所有资源都是由站长从网络上收集而来,如若本站内容侵犯了原著者的合法权益,可联系站长删除。
评论(0)