

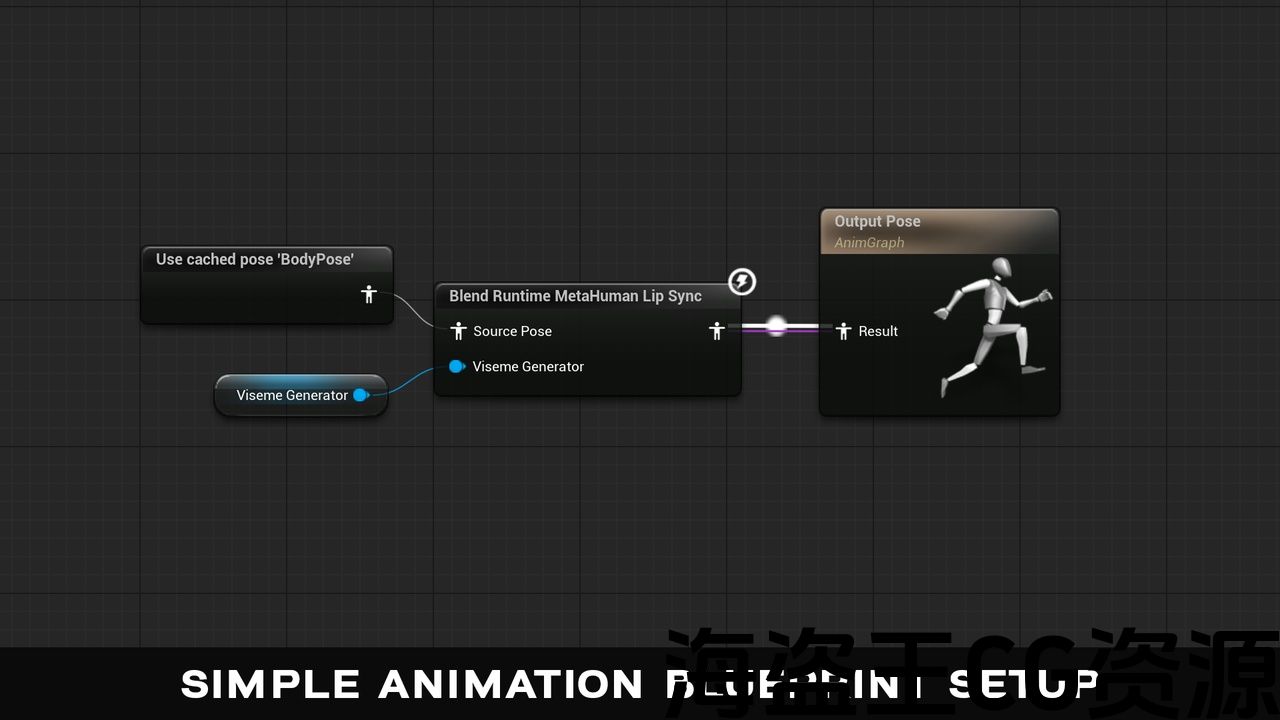
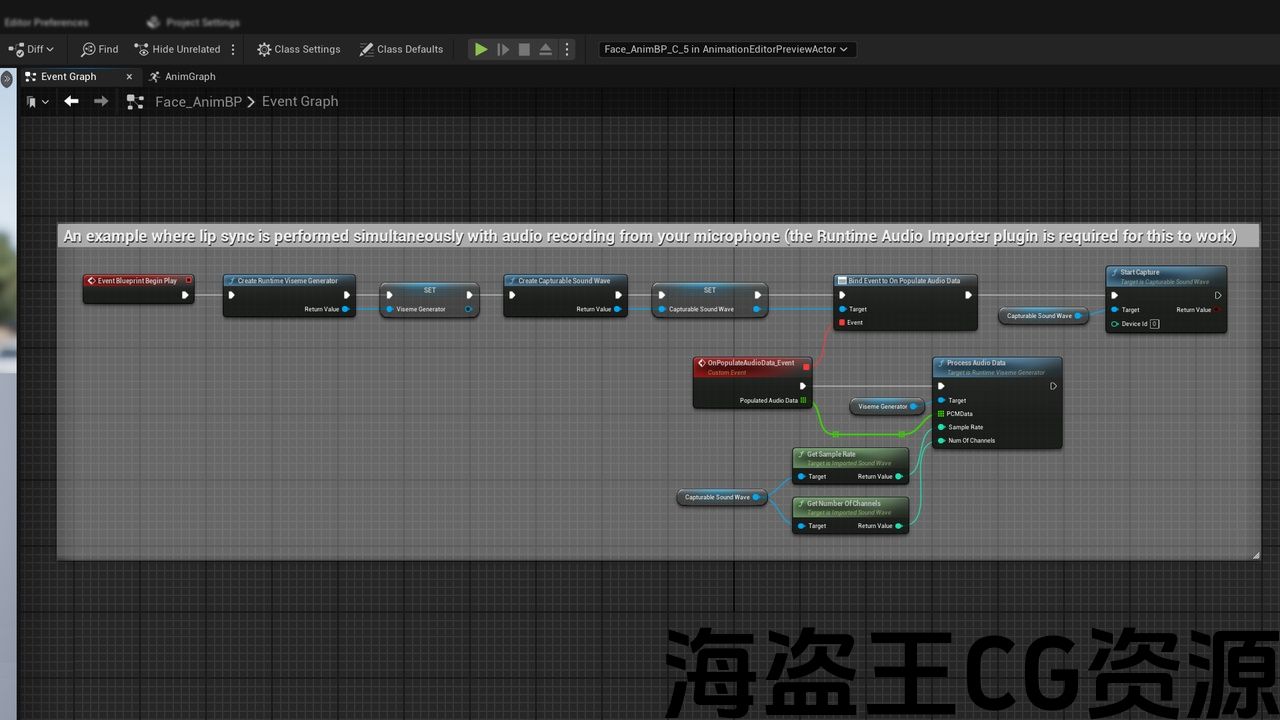
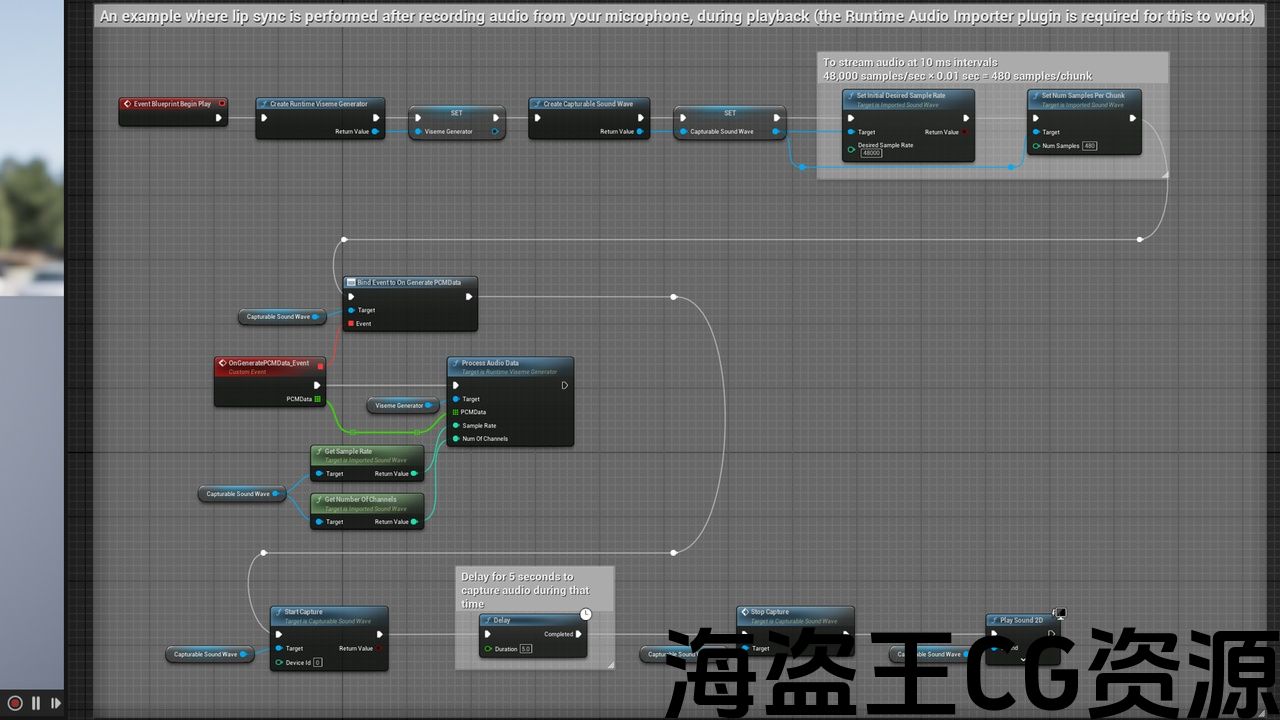
This plugin provides real-time lip synchronization for MetaHuman characters by processing audio input to generate visemes.
Features:
-
Simple, intuitive setup
-
Real-time and offline viseme generation
-
Multiple audio input sources (microphone, playback, synthesized speech, custom PCM, Pixel Streaming)
-
Direct integration with MetaHuman’s face animation system
-
Configurable interpolation settings
-
Blueprint-friendly implementation
-
No external dependencies or internet required
-
Cross-platform support (Windows, Android, Meta Quest)
该插件通过处理音频输入以生成visemes,为元字符提供实时唇形同步。
特征:
-
简单直观的设置
-
实时和离线viseme生成
-
多个音频输入源(麦克风、播放、合成语音、自定义PCM、像素流)
-
与MetaHuman的脸部动画系统直接集成
-
可配置的插值设置
-
蓝图友好实施
-
无需外部依赖或internet
-
跨平台支持(Windows,Android,Meta Quest)
ℹ️ Note: The images with plugin examples and the demo project were created using the Runtime Audio Importer and/or Runtime Text To Speech plugins. So, to follow these examples, you will need to install these plugins as well. However, you can also implement your own audio input solution without using them.
🗣️ Bring your MetaHuman and custom characters to life with zero-latency, real-time lip (+ laughter) synchronization!
Transform your digital characters with seamless, real-time lip synchronization that works completely offline and cross-platform! Watch as your characters respond naturally to speech input, creating immersive and believable conversations with minimal setup.
Quick links:
-
📦 Demo source files (UE 5.5) (requires this plugin, along with Runtime Audio Importer and Runtime Text To Speech plugins, to be installed)
-
📌 Custom Development: solutions@georgy.dev (tailored solutions for teams & organizations)
🚀 Key features:
-
Real-time Lip Sync from microphone input and any other audio sources
-
Dynamic laughter animations from detected audio cues
-
Pixel Streaming microphone support – enable live lip sync from browser-based input!
-
Offline Processing – no internet connection required
-
Cross-platform Compatibility: Windows and Meta Quest
-
Works with both MetaHuman and custom characters:
-
Popular commercial characters (Daz Genesis 8/9, Reallusion CC3/CC4, Mixamo, ReadyPlayerMe)
-
FACS-based character models
-
ARKit blendshape standard
-
Preston Blair phoneme system
-
3ds Max phoneme system
-
Any character with custom morph targets for facial expressions
-
-
Multiple Audio Sources:
-
Live microphone input (via Runtime Audio Importer’s capturable sound wave)
-
Captured audio playback (via Runtime Audio Importer’s capturable sound wave)
-
Synthesized speech (via Runtime Text To Speech)
-
From audio file/buffer
-
Custom audio source
-
💡 How it works:
The plugin processes audio input to generate visemes (visual representations of phonemes) that drive your MetaHuman’s facial animations in real-time, creating natural-looking speech movements that match the audio perfectly. It also detects laughter patterns in the audio to trigger dynamic laughing animations, adding another dimension of realism to your characters.
🎮 Perfect for:
-
Interactive NPCs and digital humans
-
Virtual assistants and guides
-
Cutscene dialogue automation
-
Live character performances
-
VR/AR experiences
-
Educational applications
-
Accessibility solutions
🌟 Works great with:
-
Runtime Audio Importer – For microphone capture and audio processing
-
Runtime Text To Speech – For synthesized speech generation
-
Runtime AI Chatbot Integrator – For ElevenLabs and OpenAI text-to-speech
ℹ️ 注: 带有插件示例的图像和演示项目是使用 运行时音频导入器 和/或 运行时文本到语音 插件。 因此,要遵循这些示例,您还需要安装这些插件。 但是,您也可以在不使用它们的情况下实现自己的音频输入解决方案。
⭐️将您的元人和自定义角色带入生活,零延迟,实时唇(+笑声)同步!
转换您的数字字符与无缝,实时唇同步,完全工作 离线状态 和 跨平台! 观看您的角色对语音输入的自然响应,以最少的设置创建身临其境和可信的对话。
快速链接:
-
🌐 产品网站
-
📦 演示源文件(UE5.5) (需要这个插件,以及 运行时音频导入器 和 运行时文本到语音 插件,待安装)
-
📄 文件编制
-
🎥 安装教程视频
-
💬 不和谐支持聊天
-
📌 海关发展: 解决方案@georgy。发展 (为团队和组织量身定制的解决方案)
🚀 主要特点:
-
实时唇同步 从麦克风输入和任何其他音频源
-
动态笑声动画 从检测到的音频线索
-
像素流式麦克风支持 -启用实时唇同步从基于浏览器的输入!
-
离线处理 -无需互联网连接
-
跨平台兼容性: 窗户 和 元任务
-
两者都适用 元人类 和 自定义字符:
-
热门商业角色(茫8/9, Reallusion CC3/CC4, 混合,混合, [医]现成的)
-
基于FACS的 人物模型
-
ARKit的 blendshape标准
-
普雷斯顿*布莱尔 音素系统
-
最大3ds 音素系统
-
任何具有面部表情自定义变形目标的角色
-
-
多个音频源:
如何运作?:
该插件处理音频输入以生成visemes(音素的视觉表示),实时驱动MetaHuman的面部动画,创建与音频完美匹配的自然外观的语音运动。 它还检测音频中的笑声模式,以触发动态的笑声动画,为您的角色添加另一个维度的现实主义。
完美的:
-
互动Npc和数字人类
-
虚拟助理和指南
-
过场对话自动化
-
现场角色表演
-
VR/AR体验
-
教育应用
-
无障碍解决方案
我的工作很好:
-
运行时音频导入器 -用于麦克风捕获和音频处理
-
运行时文本到语音 -用于合成语音生成
-
运行时AI聊天机器人集成器 -对于ElevenLabs和OpenAI文本到语音
评论(0)